Design goals
More on this later on, but as far as I know there is no consensus on how exactly a Kubernetes cluster should look, or what should be outside it, like load balancers or storage. However, if you are rocking official OpenShift from Red Hat, you have predefined pretty much everything. So take this whole setup as one of many versions. My goal is to contain as much as possible in one cluster.
Goals
- Keep everything inside the cluster, try to avoid external components as much as possible.
- Use 64bit OS – In our case, it’s DietPi (Switched from Ubuntu, it's smaller, and much easier to bootstrap from single file on first boot.). I wanted arm64 because storage solutions for Kubernetes do not support arm32 (more on this later).
- Use distributed block storage for persistent storage for pods.
- End up with FaaS (Function as a Service) platform for python (and other languages).
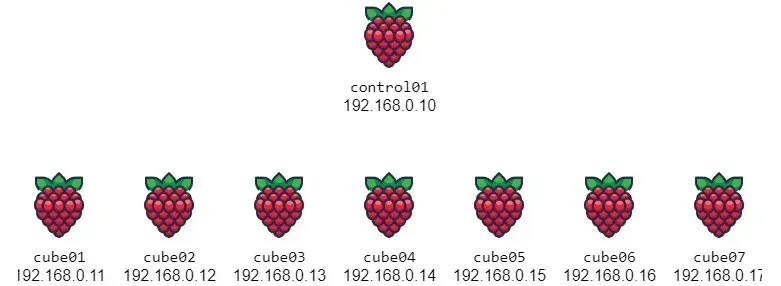
High Availability (Issue)
Originally I had 3 control nodes, but I decided to use only one. After some testing I had serious performance issues with ETCD syncing in new versions of K3s. Maybe using an external database would be better, but that would require external dependencies. So one control node will have to work, it is a single point of failure for us though.
Resource issues
Another thing usually omitted from discussion is the limitation of resources. You need to keep in mind that pods require disk space to exist. Yes, they exist temporarily on worker nodes, not tied to a specific server. Yet, they consume space. The more pods you are running more space you will need. Same shit for RAM. If you have pods that consume more RAM than worker nodes have, it might not run at all… Keep this in mind when designing your cluster/apps. Make sure the workers have enough resources. Control servers can be as simple as possible as they do very little except keeping the workers in check.